
背景介绍
在互联网公司里面,通常都会监控成千上万的时间序列,用于保障整个系统或者平台的稳定性。在这种情况下,如果能够对多条时间序列之间判断其是否相关,则对于监控而言是非常有效的。基于以上的实际情况,清华大学与 Alibaba 集团在2019年一起合作了论文《CoFlux: Robustly Correlating KPIs by Fluctuations for Service Troubleshooting》,并且发表在 IWQos 2019 上。CoFlux 这个方法可以对多条时间序列来做分析,并且主要用途包括以下几点:
- 告警压缩和收敛;
- 推荐与已知告警相关的 Top N 的告警;
- 在已有的业务范围内(例如数据库的实例)构建异常波动传播链;

CoFlux 的整体介绍
从论文的介绍中来看,CoFlux 的输入和输出分别是:
输入:两条时间序列
输出:这两条时间序列的以下信息
- 波动相关性:两条时间序列是否存在波动相关性?
- 前后顺序:如果两条时间序列相关,那么它们的前后波动顺序是什么?是同时发生异常还是存在固定的前后顺序?
- 方向性:如果两条时间序列是波动相关的,那么它们的波动方向是什么?是一致还是相反?
Remark. CoFlux 的关键点就是并没有对时间序列做异常检测算法,而是直接从时间序列的历史数据(历史半个月或者一个月)出发,判断两条时间序列之间的波动相关性,并且进一步的分析先后顺序与波动方向。
从论文的介绍中来看,CoFlux 的流程图如下图所示:

如果两条时间序列 
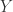

CoFlux 的细节阐述
已知一个长度是 

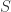

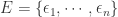

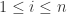

在 CoFlux 算法的内部,根据不同的参数使用了总共 86 个 detector,大致列举如下:
- Difference:根据昨天,七天前的数据来做差分;
- Holt-Winters:
;
- 历史上的均值 & 历史上的中位数:1,2,3,4 周;
- TSD & TSD 中位数:1,2,3,4 周;
- Wavelet:1,3,5,7 天;
- 移动平均算法:MA,WMA,EWMA。PS:根据作者们的说法,在这里,MA等方法并不适用。

根据直觉来看,
- 对于任何一条时间序列 kpi,总有一个 detector 可以相对准确地提炼到其波动特征;
- 如果两条时间序列
Remark. 两条时间序列的波动特征可以对齐同一个 detector,也可以不做对齐工作。如果是前者的话,时间复杂度低;后者的话,时间复杂度高。
下图是从时间序列中提取波动特征曲线的案例:

提炼时间序列的波动曲线特征只是第一步,后续 CoFlux 还有几个关键的步骤:
- 特征工程的扩大(amplify): 对波动序列特征进行放大,让某些波动序列特征更加明显;
- Correlation Measurement:用于解决时间序列存在时间前后的漂移,两条时间序列之间存在 lag 的情况,因此需要对其中一条时间序列做平移操作;
- CoFlux 考虑了历史数据(历史半个月或者一个月)作为参考,并且一个范围内的 kpi 数量不超过 60 条;
下面来一一讲解这些技术方案,对于每一条波动特征曲线(Flux-Features),按照以下几个步骤来进行操作:
Step 1:对波动特征曲线


Step 2:对归一化之后的波动特征曲线做特征放大(feature amplification):定义函数 
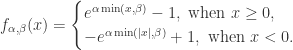
则

Step 3:对于两条放大之后的波动特征曲线(amplified flux features)

令

这里的 0 的个数是 
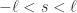
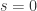


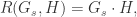
这里的 
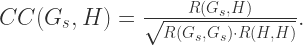
由于波动有可能是反向的,那么在这里我们不仅要考虑相关性是大于零的情况,也需要考虑小于零的情况。于是,


则最小值或者最大值的指标分别是

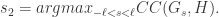
令

从定义中可以看出,
![FCC(G,H) \in [-1,1]](https://s0.wp.com/latex.php?latex=FCC%28G%2CH%29+%5Cin+%5B-1%2C1%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002)

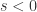
在最后的相关性分析里面,其实伪代码正如论文中所示。先考虑是否存在相关性,再考虑基于相关性下的先后顺序和波动方向。

CoFlux 的实战效果
从论文中看,CoFlux 的数据集基本上是小于 60 条时间序列曲线。其中包括 CPU,错误率,错误数,内存使用率,成功率等不同的指标。


从运行时间上来看,对于一周的时间序列集合(< 60条)而言,CoFlux 基本上能够在 30 分钟内计算完毕,得到最终的运算结果。

其效果的评价指标基本上就是机器学习中的常见评价指标了,准确率,召回率之类的。

从 F1-Score 的评价指标来看,CoFlux 的效果优于其他算法。

告警压缩
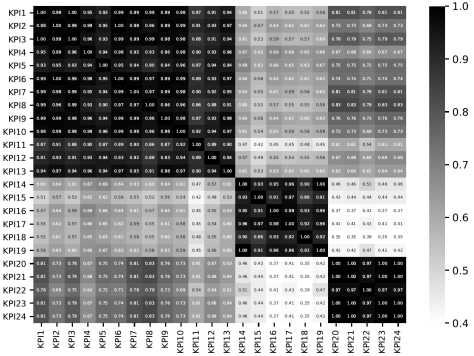
如果对时间序列之间进行告警压缩的话,其实可以大量减少运维人员的工作量。在 CoFlux 里面,时间序列曲线被分成了三类,也就是三个颜色最深的模块。因此 21 条时间序列的告警量在实际中有可能只有三条告警。
告警关联
在实际运维场景中,除了对告警进行压缩之外,也需要对告警进行关联性的分析。例如一条告警发生了,运维人员都希望知道与它相关的其他告警是什么,这样可以方便运维人员定位问题。

构建告警关系链
在一些相对封闭的场景下,例如 mysql 数据库,通过对它里面的时间序列进行分析。不仅可以得到告警之间是否存在相关性,还可以对先后顺序,波动顺序进行分析。

结论
时间序列之间的联动分析是在运维领域场景下的常见技术,不仅可以做告警的压缩,也能够做告警的关联,还能够构建告警的关系链。在未来的工作中,作者们提到将会用深度学习的方法来进行关联和告警的分析,从而进一步加深对时间序列的研究。
